This post is part of the New Functionality In Microsoft Dynamics 365 Business Central 2023 Wave 2 series in which I am taking a look at the new functionality introduced in Microsoft Dynamics 365 Business Central 2023 Wave 2.
This post is part of the New Functionality In Microsoft Dynamics 365 Business Central 2023 Wave 2 series in which I am taking a look at the new functionality introduced in Microsoft Dynamics 365 Business Central 2023 Wave 2.
The eighteenth of the new functionality in the Development section is Segment AL code and reduce naming conflicts with namespaces.
AL for Business Central will now support namespaces, similar to other code languages. Namespaces provide a way of organizing objects and code in a logical and hierarchical manner. They can be used to help avoid naming conflicts between different extensions, making it easier to maintain and understand extensions, including the relationship between different objects.
Enabled for: Admins, makers, marketers, or analysts, automatically
Public Preview: Aug 2023
General Availability: Oct 2023
Feature Details
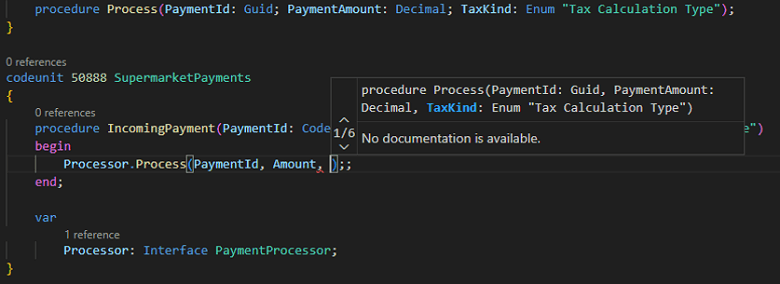
An AL file can now define a namespace at the top, which will apply to all objects in the code file. A given object can only belong to one namespace, but the same namespace can be used for multiple AL files and objects.
When objects are resolved, the closest scope is used first. Therefore, to resolve to a similarly named object in a dependent extension, the reference must use a fully qualified name. Alternatively, it’s possible to define using directives to include external namespaces and thereby omit fully qualifying names.
Because namespaces are useful for logical segmentation of extensions, the AL Explorer also shows namespaces for objects and allows grouping objects by namespace, making it easier to discover related objects, focus on app subareas, and identify inconsistencies when adding new objects.